Hello! It's been a while! On behalf of the Mellon crew, I'd like to first acknowledge that yes, it's been nearly eight weeks since our last post...
...but we're back! Mike, Dallas and I have been busy preparing for an workshop next week at
Personal Digital Archiving (PDA) 2016 on free and/or open source tools for digital preservation. My part's on the theory and practice of migrating files to preservation formats, including tutorials for different file types (with single and batch conversion examples using both GUIs and the command line). I thought I'd share it here.
For your convenience, here's a little navigation bar that will be updated as new posts come out.
- Theory
- Practice:
- Still Images
- Text(ual) Content
- Audio and Video
First up, some theory.
I'll say right off the bat that, yes, even though migration is a standard part of our current (
and future) ingest procedures, it is probably less important than good organization, description and redundant storage, especially for personal (i.e.,
lay person-al) digital archives. That being said, technology changes all the time. At some point you'll need a strategy to deal with the fact that you can't read your parent's extension-less Word 2.0 file from 1991 (which, by the way, you
know proves that you're the favorite child) on your fancy new computer with your fancy new version of Word, especially because it was saved on a 3.5-inch floppy disk and you don't have a bay for it. You've also probably never heard of DROID or anything like it, so you won't even know in the first place that it's a Word file.
The Performance Model and the Fundamental Nature of Digital Records
I believe I was first introduced to the National Library of Australia's Performance Model, detailed in their article entitled "An Approach to the Preservation of Digital Records," at the
DigCCurr Professional Institute back in 2012. As is the case with just about any other model, it's overly simple and, mostly for that reason, it has its issues. It's also a bit dated (2002) and in places this shows. However, I think it does a good job of framing a discussion about migrating files to preservation formats, so we're going to use it!
First, let's think about the world of physical records. You might say it looks something like this:
In this world, a researcher can have a "direct experience" of a record, with just their eyes. No mediation required.
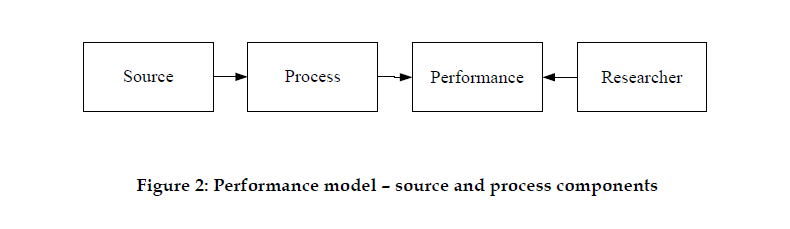
Now, let's think about the world of digital records which, you might say, looks something like this:
In this world, a researcher can't really have a direct experience of a record. If they did, they'd be looking at a bunch of meaningless (to human eyes, at least) 1s and 0s. They might also have
escaped from the Matrix. Instead, some sort of
process has to be performed on the
source (no longer, as we'll see, considered the record), and the thing the researcher interacts with is a type of
performance.
Put a little more concretely:
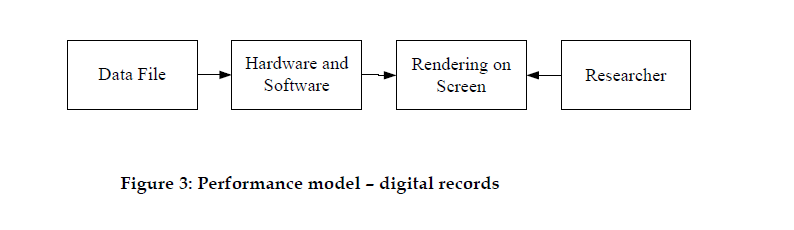
A source is basically a data file, like the Word 2.0 document provided as an example above or anything else you can think of that's sitting on your hard drive. The data file is formatted in a particular way, and gets processed by some combination of hardware and software that can understand it. Usually this combination needs to be fairly specific. To quote the article, "a Word source requires the correct version of the Word application, using a Windows operating system, which is installed on a suitable Intel computer" (p. 9). That's not entirely accurate, but I think you get the point. The performance, then, becomes the way that the data file, through the hardware and software, gets rendered on the screen. This performance, the authors argue, is what the researcher is after--not the original data file or the hardware and software.
Make sense?
Migration
Migration, in this context, is just a fancy word for converting a digital object form one data format to another, for example, from Word 2.0 file to a Portable Document Format (PDF) file. We'll get lots of practice with this when we look later at migrating still images and text(ual) content as well as audio and video.
It's a strategy (I'll talk briefly about others later) that gets employed to handle the digital preservation scenario outlined above. In performance model terms, migration converts a source object from an obsolete or proprietary format into a current or open format so that a current process (hopefully a somewhat less specific combination of hardware and software) can render it.
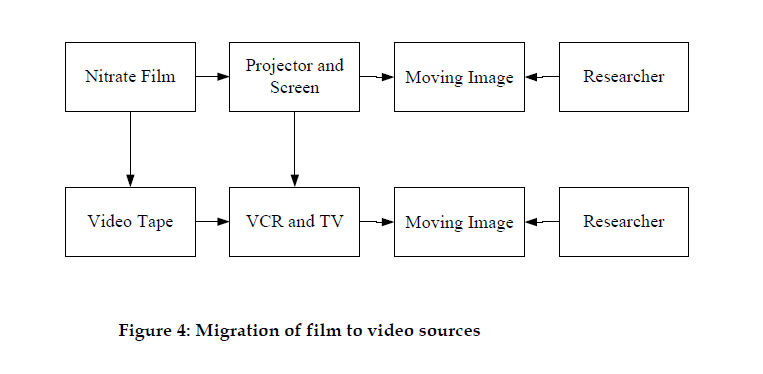
Consider this analogous (get it?) scenario from the audiovisual world:
Nitrate film, which requires a projector and screen to produce a moving image, is an unstable source. In this scenario, it gets migrated to video tape, recognized (at least in 2002) as a more stable source. This new source requires a new process to produce a moving image, namely, a VCR and TV. In both cases, though, and this is the important part, it's the performance (i.e., the moving image) that becomes the record that the researcher is interested in. The same is true for migrations like the ones we'll be doing.
The Concept of Essence, or Significant Characteristics
That all sounds fine and dandy until you start to think that changing files sounds (and, in fact, is) pretty risky! How do we ensure the the moving image from the videotape on a VCR and TV is the same moving image as the earlier one from the nitrate film on a projector and screen? I'll quote the article at length here:
The performance model demonstrates that digital records are not stable art[i]facts; instead they are a series of performances across time. Each performance is a combination of characteristics, some of which are incidental and some of which are essential to the meaning of the performance. The essential characteristics are what we call the ‘essence’ of a record.
These essential characteristics (also known as
significant characteristics or, sometimes, significant properties, although this usage seems to be falling out of favor) are what's really important about a record; they provide "a formal mechanism for determining the characteristics that must be preserved for the record to maintain its meaning over time" (p. 13).
Consider our Word 2.0 file. It's a type of word processing document. The essential characteristics may include:
- it's message:
- the message's qualifiers:
- formatting such as bolded text;
- font type and size;
- layout;
- bullets;
- color; and
- embedded graphics.
These were, at least, the characteristics deployed by the author to get the message across to a reader or to help out with its comprehension.
The lesson here is that migration is a great strategy for overcoming the challenges of digital preservation. If you have a way to check that significant characteristics for source files match on either side of a migration (we'll get some practice with this too in upcoming posts), it's an even better strategy. [1][2]
Alright, enough theory.
The Elephant in the Room: Emulation
Since I'm talking to a bunch of archivists, I'll add that migration isn't the only strategy for overcoming the challenges of digital preservation. It's often contrasted with emulation, an approach that, using the Performance Model, "keeps the source digital object in its original data format but recreates some or all of the processes (for instance, the hardware configuration or software applications such as operating systems), enabling the performance to be recreated on current computers” (p. 12). There are convincing arguments to be made in favor of both approaches, and it seems like they all come down to what one considers to be the true essence of a digital record!
Now, migration definitely has its disadvantages. It's costly and time-consuming (but to be fair, so is emulation) and the actual process, in a production environment, is error-prone.
[3] That being said, it's what's available for many institutions, at least in the US (
Archivematica,
Preservica and
Rosetta, for example, all employ this strategy). I'll also reiterate here that migration and emulation are both probably secondary to good organization, description and redundant storage of digital archives, as well as migrating content off of legacy storage media.
When I first learned about digital curation and preservation, I was taught that emulation was a kind of "will be nice after more research and development, maybe" strategy. I think this perception is still fairly common (we keep our original files around, even the weird ones, for example, just in case that research and development ever happens). However, I'm not so convinced anymore.
Emulation as a Service seems particularly exciting for enabling emulation at scale, even at smaller institutions.
In the end, migration doesn't have to be your exclusive, or even primary, digital preservation strategy. It is a trusted strategy, though, for many libraries and archives. If you'd like to explore it in a little more depth, stay tuned for upcoming posts!
---
[1] Of course, this is the kind of thing that sounds great in theory, but in practice I find it's really hard to define significant characteristics, especially the way we currently try to do it according to file format or type. Pagination of a word processing document, for example, could be an essential or incidental characteristic depending on how that document gets used, or if it needs to be cited. You'd also probably ruffle some feathers if you said explicitly (as the article says implicitly) that file format is an incidental characteristic.
[2] This kind of significant characteristics check (currently, at least) isn't part Archivematica, unless you count checking that a migrated file's size isn't 0. That's not to call them out or anything, just to say that we should cover making this type of customization at Archivematica Camp 2016!
[3] We've done migrations on old word processing documents that resulted in 15-20 pages of random characters on either side of their one meaningful page--the essential characteristics were there, in other words, they were just mixed in with so many incidental characteristics they were hard to find.