
As you might have guessed, the Storage Service has to do with storage. Specifically, it allows users to configure the storage spaces (e.g., transfer source locations, AIP and DIP locations, etc.) with which Archivematica interacts.
In short, the Archivematica Storage Service is the heart of Archivematica.
 |
| Blood Flow in the Heart |
| Information Flow in the Archivematica Storage Service |
You can learn more about the heart here.
You can learn more about the Archivematica Storage Service here in this post. (And here. And here.)
Storage Service Structure and Current Use
The Storage Service is made up of a number of different entities: Pipelines, Spaces, Locations and Packages. A Pipeline has Spaces, a Space has Locations; and a Location has Packages:Pipelines
Pipelines are essentially Archivematica installations registered by the Storage Service. Although institutions may have many pipelines, we currently use just one for born-digital processing. That being said, we've imagined scenarios where we'd consider adding more pipelines, if another one of the libraries or archives at the University of Michigan wanted to use Archivematica, for example, or if we ever wanted to use Archivematica for more than this one, fairly well-defined workflow and material type.Spaces
Pipelines have one or more spaces. Spaces allow Archivematica to connect to physical storage (e.g., a local filesystem or a NFS, or even DSpace/Fedora via SWORD v. 2, LOCKSS, DuraCloud or Arkivum), and users input all the necessary information (e.g., remote hostname and location of the export) for Archivematica to do so.We make use of a number of local filesystem spaces that point to:
- a "dropbox" that donors and field archivists use to transfer material;
- a "legacy" space (really, two spaces) containing our old, pre-Archivematica backlog, where we have the automation-tools pointed; and
- an "archivematica" space that Archivematica uses for ingest processes.
- Archivist must enter a DSpace username and password--these are used to authenticate with DSpace.
- Archivists must also enter a policy for restricted metadata, in JSON, to override any defaults in DSpace. When AIPs are "repackaged" into "objects" and "metadata" packages, the metadata package will get this policy. In our case, this points to a DSpace "group" that includes a handful of curation and reference archivists here, restricting access to only those archivists.
- Finally, archivists must select an "Archive format" option. Since we're depositing "packages" of digital objects to DSpace (and DSpace only accepts single objects), you have to package them into a 7z or ZIP file. We make use of the latter, our thinking being that the ".zip" extension is fairly ubiquitous, and that as such there's a greater chance that researchers will recognize it (and know what to do with it).
Locations
Spaces have one or more locations, and locations are where you get into the knitty gritty of associating an individual location on physical storage with particular "purposes" in Archivematica (e.g., transfer source locations, AIP and DIP locations, etc.). This next part was a bit confusing to me the first time I read it, so I'll quote directly from the documentation: "Each Location is associated with at least one pipeline; with the exception of Backlog and Currently Processing locations, for which there must be exactly one per pipeline, a pipeline can have multiple instances of any location, and a location can be associated with any number of pipelines."We make use of the following locations (organized by purpose):
- AIP Storage
- We have a number of these locations that correspond to DSpace collections. This is configured by pointing the Storage Service (and the DSpace space) to the DSpace REST API endpoint for that collection, e.g., https://dev.deepblue.lib.umich.edu/swordv2/collection/TEMP-BOGUS/236280, and giving it a name that you'll see in a dropdown when you get to the store AIP microservice in Archivematica:

- We also have one location on a local filesystem for for content with restrictions. These AIPs end up going through a more specialized workflow that matches PREMIS Rights Statements we record in Archivematica with the appropriate "group" or access profile in DSpace, functionality that is not included with the standard DSpace integration.
- Currently Processing: This is the location used by the Archivematica pipeline as it runs transfers through its various microservices. We've learned the hard way that this space takes a lot of management! We frequently run into 500 errors with the automation-tools that end up being caused by this space being full. Part of the reason it fills up quickly is that Archivematica is very conservative, holding onto copies on copies on copies of transfers in various subdirectories for various reasons, e.g., "rejected" (used when transfers are rejected in the dashboard), "failed" (used when transfers fail for some reason, usually because they're too big, which just exacerbates the "being full" problem) and "tmp" directories. These can be emptied through the "Administration" --> "Processing storage usage" tab of the dashboard, but we ended up just making a daily cronjob to empty these out.
- Storage Service Internal Processing: This is required for the Storage Service to move run, must be locally available to the storage service, and must not be associated with any pipelines.
- Transfer Backlog: This is where SIPs go when you select the "Send to backlog" option for "Create SIP(s)" in the "Administration --> Processing configuration" tab of the dashboard. This is an optional workflow step, but we make heavy use of it. For us, there can be some time lag between an initial accession of material and its subsequent processing and deposit to DeepBlue. This backlog location is safe and secure and serves as a temporary, "minimally viable" preservation environment for the original digital objects and the logs and METS file generated by Archivematica's initial transfer process. With Archivematica 1.6, thanks to some transfer backlog management development work by Simon Fraser University Archives, you can use a new "Backlog" tab in the dashboard to search and view backlogged transfers, download entire transfers or items from backlog and even perform transfer deletion requests.
- Transfer Source: Archivematica looks to these locations when creating a new transfer. As mentioned earlier, we use a couple of these, a "dropbox" that donors and field archivists use to transfer material and a "legacy" space containing our old, pre-Archivematica backlog. Material in here is accessed (sometimes slowly if there's a lot in there!) when creating a transfer through the dashboard:
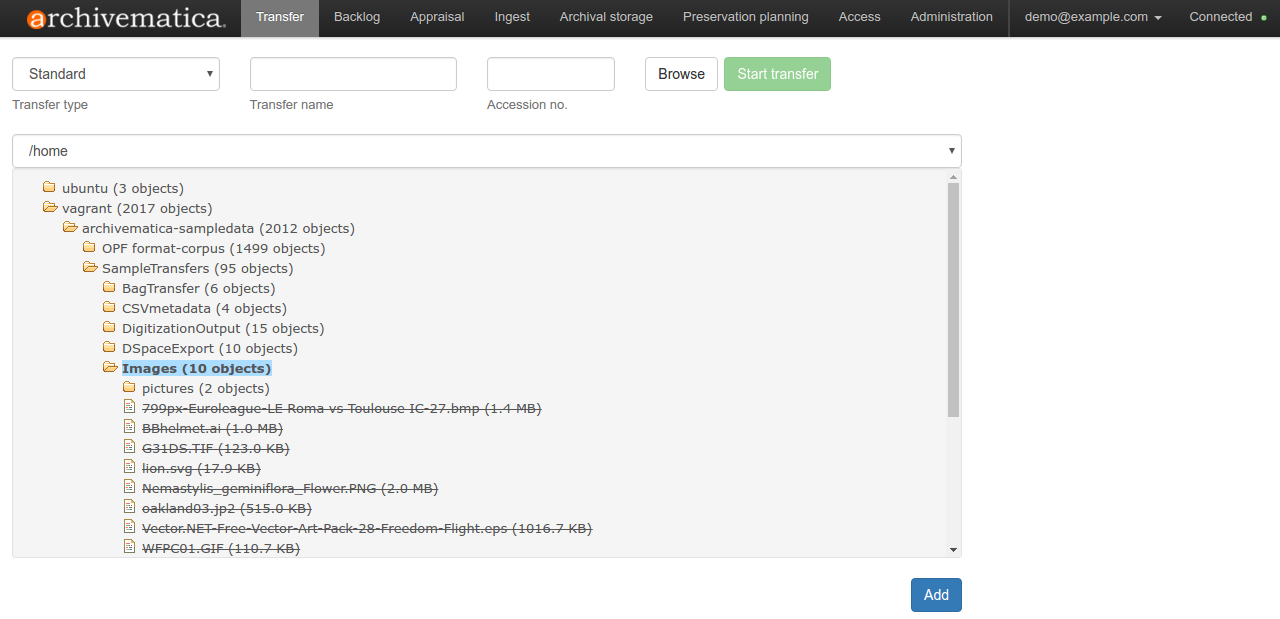 |
| Selecting transfer source directories |
Packages
Packages are Transfers, SIPs, AIPs and DIPs uploaded to a location managed by the storage service. The Storage Service is also the place where requests to delete packages are fulfilled by an administrator.Future Ideas for Storage Service Usage
You may have seen our recent post to the Archivematica Tech list about an API endpoint for posting locations to a space. We're interested in this to try to reuse metadata and further automate our own workflows, for example, in this Resource-to-Collection command-line utility we're working on that:- creates or updates a DSpace Collection from an ArchivesSpace Resource (using the DSpace API);
- creates an Archivematica Storage Service Location for the DSpace Collection (in lieu of the endpoint, we're currently using Selenium with Python for this part);
- creates and links an ArchivesSpace Digital Object for the DSpace Collection to the ArchivesSpace Resource (using the ArchivesSpace API); and
- notifies the processor (using their Archivematica username) via a message on Slack (using the Slack API).
| Deposit away, Dallas! |
Who knows, maybe this or something like it could be a button in ArchivesSpace one day.
Well, that's enough from us! How do you use the Storage Service? As always, please feel free to leave a comment or drop us an email: bhl-mellon-grant [at] umich [dot] edu. Thanks!
No comments:
Post a Comment